
LLM Workflows in the Financial Space
Building a Transcript Summary and thoughts on LLM use cases in financial data

I’ve been thinking a lot about LLM (large language model) use cases in the financial space lately. Last month, we (Koyfin) introduced our first scaled LLM-enabled feature in Transcript Summaries. While this feature is what I shall refer to as table stakes1, it doesn’t take away from what we have built. I’ve had a glimpse into how the sausage is made for “simpler” adaptations like summaries as well as more complicated, generative features (which we are working on now). I‘m going to briefly discuss the way our summaries were designed and how that makes it unique. Then I am going to segue into a broader conversation about LLMs and the financial analysis & data market.
Transcript Summaries
Corporate transcripts are packed with critical information. But they are also verbose and full of ‘fluff’. A good summary should extract the vital information and discard said fluff. They should do this one task well, and they don’t require interactivity.
When embarking on this project, I observed how peers tackled this. There were a lot of examples to choose from (hence, table stakes). I noticed a lack of vision and understanding of what a user wants a summary to be. Most often, the summaries would whittle down a transcript into a handful of bullet points, which read more like a high-level earnings news highlight— “American Express reported $X.XX in EPS… Management suggested they are optimistic about YYYY”.
On the depth scale, the dial was turned all the way to ‘As little information as possible without the page being empty’. A typical earnings call transcript will take an avid reader ~20 minutes to read, while most ‘summaries’ I’ve seen out there take ~20 seconds. They optimise for extreme brevity. We took a slightly different approach, aiming for ~3 minutes to read.
We didn’t want them to be ‘as concise as possible’ at the expense of, you know, informing the reader. Instead, we focused on reorganising the important information into easier-to-consume chunks and removing the filler.
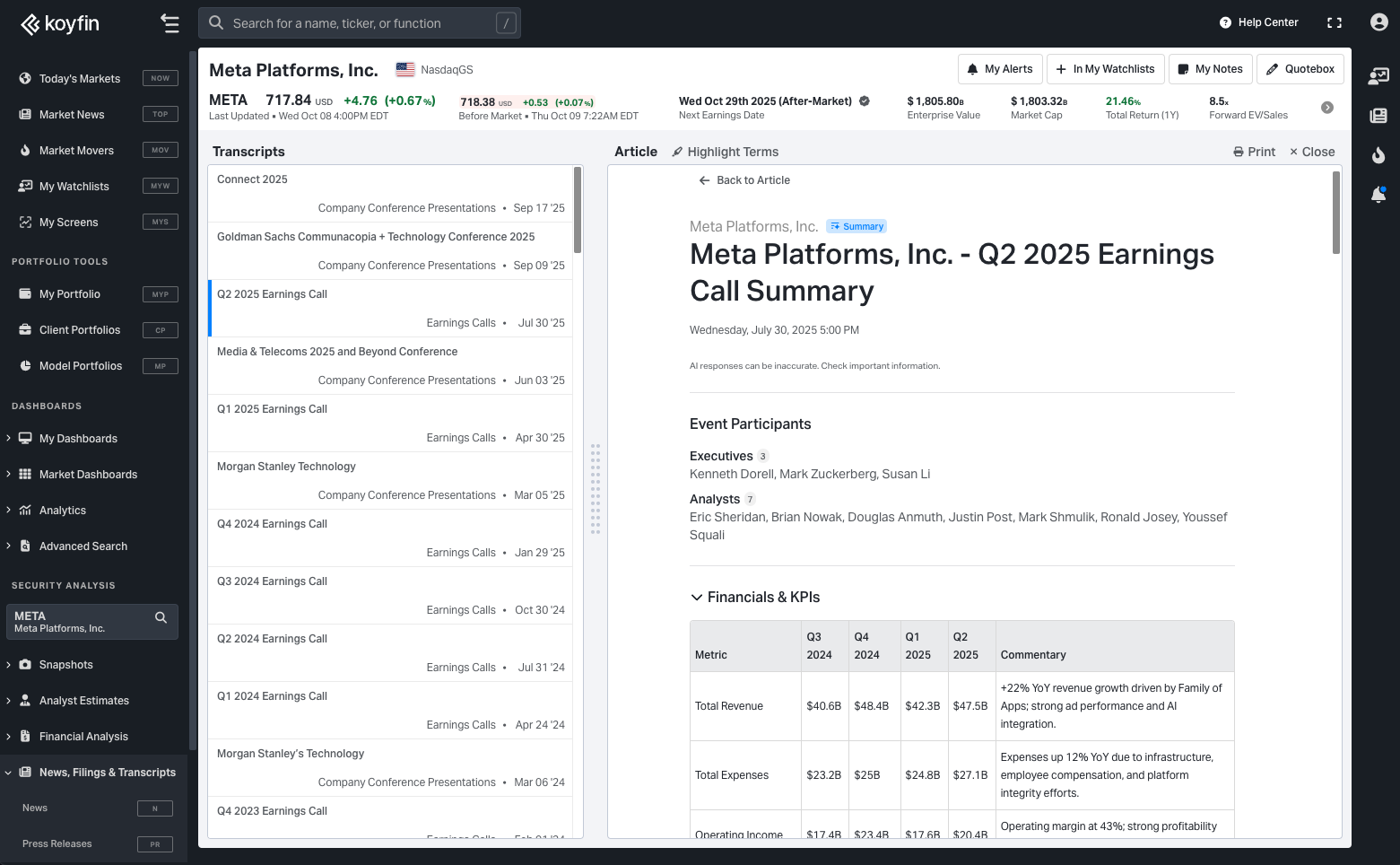
Every unique type of event (earnings call, M&A, special call, etc) dynamically takes on its own structure and formatting to organise the summary into segments that matter and are relevant to that particular event. In what is arguably the most diverse event type, earnings calls, the summary will adjust to centre around the individual qualities of a company. Sections may include KPI trend tables, geographic commentary, specific business segment results and commentary, risks, guidance, and a concise Q&A breakdown.
As a result, I believe these summaries are higher quality, balancing the verbosity of a full transcript vs. the lack of depth in providing a few bullets. I implore you to try a few and let me know what you think.
The reason we optimised for organisation over brevity is that we felt this is more aligned with the actual workflow. The problem users have is not that they want to consume an entire transcript in 20 seconds2 (which is not actually possible). The problem is that transcripts are conversations, and the critical information is buried amongst a large corpus of word salad. Extracting that critical information and presenting it legibly was the goal. And if that takes a few more minutes to read front to back, that’s fine.
While a seemingly simple3 user experience, transcript summaries are one example of how LLMs can be used to enhance an existing workflow. The user doesn’t necessarily care that this summary was created using an LLM. The important thing is that an LLM made this workflow possible and seamless. This is the theme I want to pick at a little more. Over time, I am gravitating towards the idea that incorporating AI into a product is less about slapping AI labels onto things and more about enhancing or creating new workflows.
LLM Workflows are Everywhere
The wide-scale adoption of LLMs has captured society’s attention. There is no doubt about that. As they endure their ‘hockey stick’ moment, part of what is so exciting is the vast potential in both consumer and enterprise applications. A huge portion of the world’s inhabitants have now tasted one of the most mundane applications of modern LLM use cases, the chat-based interface, through the likes of ChatGPT, Gemini, and others.
While it feels criminal to call this mundane when it still (to me at least) feels like magic, the reality is that people have become accustomed to this offering. We are getting past the phase of accepting suboptimal responses, and we expect them to be high quality. In November 2022, ChatGPT 3.5 was born, and the genie escaped the bottle. Five days later, it reached 1 million users. A couple of months later, it hit 100 million users. Today, the likes of OpenAI’s ChatGPT and Alphabet’s Gemini have monthly actives (MAUs) in the hundreds of millions. I am sure this moment in history will be documented for decades to come.
Thanks to the desire of gargantuan enterprises like Nvidia, Microsoft, Meta, Alphabet (and more) to pump capital into this space for fear of being a victim of the innovator’s dilemma, this product has already become somewhat of a commodity. It’s not incredibly expensive to the consumer, it’s widely available, and there are several institutions that develop and offer these frontier models in a consumer-friendly package (ChatGPT, Gemini, etc). There are thousands of enterprises building products that are essentially ‘wrappers’ on top of these models, too.
The latter is particularly exciting. As with most commodities, there is an oligopoly of firms supplying the raw materials, but the exciting part is the layer above in which those goods are transformed to create an unfathomable number of ‘new’ product offerings. It is those offerings which are so exciting.
We’ve already seen an abundance of ‘AI Helper’ style tools pop up in all of our favourite software. We’ve also witnessed early innings of how these models can be blended with hardware applications in cases like Meta’s ‘Ray-Ban Display’ glasses, which pair with a neural wristband, exploring the potential of the ‘next screen’ to displace smartphones.
I won’t pretend to have any insight into what this space looks like in ten years, but I am excited about what the world’s greatest minds come up with.
LLMs are Eating the World
Some time ago (2011), the phrase “software is eating the world” was coined by Marc Andreessen in a Wall Street Journal article. There, Marc was highlighting a trend that had already been underway for some time.
“We are in the middle of a dramatic and broad technological and economic shift in which software companies are poised to take over large swathes of the economy.”
In this article, he cited Netflix replacing Blockbuster, Amazon transforming retail, and software transforming mechanical vehicles into computers on wheels as early examples. It became the defining mantra of the 2010s. It feels like we are now seeing a similar theme, this time orchestrated by LLMs.
Today, I am going to be focusing on the financial space, but I suspect the ramifications on labour demand and consumption behaviours will reverberate throughout the global economy for years to come.
Customer support is a well-documented use case. Companies across all sectors and industries have already implemented LLM-powered support agents that essentially hook up to their internal knowledge base to solve common and simple user support cases. We did this at Koyfin over a year ago now. Here are a couple of examples, but there are many more.
Intuit (INTU) claimed they’ve seen a “15% reduction in contact rate in the past year” for their customer support desk after implementing GenAI4.
London Stock Exchange Group (LSEG) told investors that “More than 80% of customer queries are now resolved using AI customer support tools” in July5.
Lyft (LYFT) issued a press release in February 2025 suggesting that their “customer care AI assistant has reduced the average customer service resolution time by 87% and is resolving thousands of customer requests each day”.
Outside of directly replacing labour units in a one-for-one manner, you have to consider the argument that LLMs make a single unit of labour more efficient. Suppose it helps a developer ship 25% more code. Does that mean you now only need four developers instead of five? If product requirements and PRDs can be spun up in seconds with the help of co-pilots, does your organisation need so many product managers?
In a 2025 paper6, funded by Microsoft, the authors suggested that job titles such as interpreters and translators, historians, sales representatives, writers, authors, telephone operators, concierges, data scientists, models, and market research analysts (among others) were most at risk of displacement by AI.
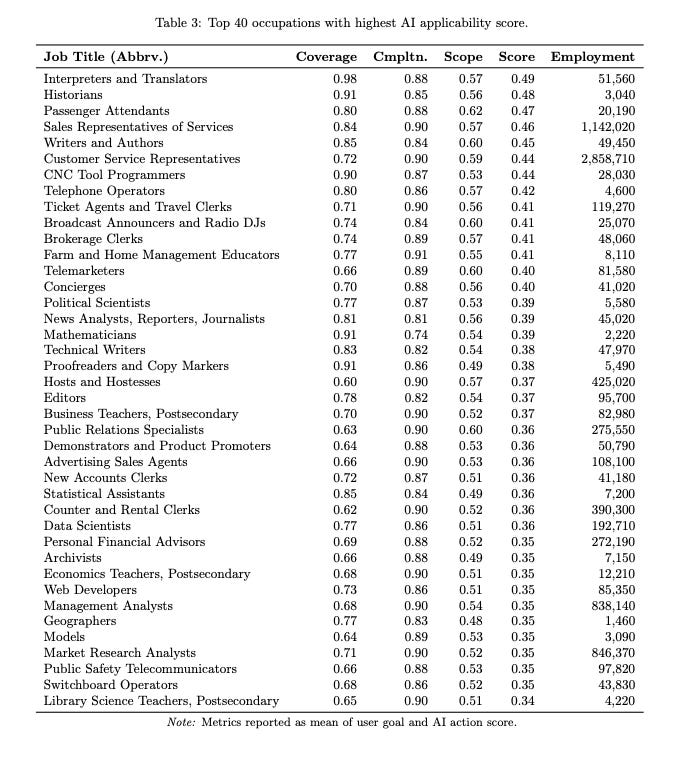
I have no idea what ultimately comes of this, but I find it likely that both arguments will be true. Namely, that LLMs will make certain labour units more efficient, and that this will result in fewer units of labour being required for particular roles or functions. Similarly, I feel that efficiency gains are context-dependent. This idea of labour being replaced by technology is not exactly a new phenomenon.
I was watching a documentary about Cadbury’s (the chocolate maker) recently. In that documentary, they spoke with veterans of their Bournville production facility based in the UK. In 1878, the site employed ~200 workers. By 1899, the site had more than 2,600 employees. By the early 1900s, a village was formed7 to house employees.
“George Cadbury was a housing reformer interested in improving the living conditions of working people in addition to advancing working practises. Having built some houses for key workers, in 1895 he bought 120 acres near the works and began to build Bournville village”.
Bournville village was born. From thereon, the village developed into a community with its own shops, schools, playgrounds, colleges, and various other recreational facilities. It is thought that by the mid-20th century, the Bournville facility employed between 7,000 to 9,000 people. The veterans from the documentary reminisced about this period and talked about how this gradually came to an end as more machinery was introduced, displacing the need for thousands of workers. An older gentleman, being interviewed on the facility floor, looked around the room, noting that hundreds of workers would clock in and out of the building every day and that now it only requires a handful of bodies to ensure production runs smoothly.
This trend was accelerated in the 2010s after Cadbury was acquired by Mondelēz International, which sought to industrialise the plant further. Today, the plant employs some 1,000 people, and the village ceased to be ‘for employees only’ decades ago. Such is the cost of progress and efficiency.
I have no doubt the age of LLMs will cause mass disruption to the workforce as we know it today, but I am equally optimistic that we humans will figure out some other use for those idle hands in the long term. We have a knack for this, and history confirms as such. Nowhere will this workflow transformation be more visible or fiercely defended than in financial data.
LLM Workflows in the Financial Space
In the financial world, there are a small group of kingpins specialising in the realm of financial data. Companies such as London Stock Exchange Group (LSEG), Standard & Poor’s (SPGI), Factset (FDS), Bloomberg, and Morningstar (MORN). I will lazily refer to these companies as the ‘Big 5’. Between them, they carry a significant competitive advantage in the fact that they “own” and are the licensors of datasets covering, but not limited to, global ETFs, Mutual Funds, Equities, SMAs, Credit Ratings, Fixed Income Data, News and more8.
To use this data commercially, as a business, you likely have to go through at least one of these companies to license their data.
Focusing on the financial data & analytics market for a second, let’s say there are two levels. The base layer is the aforementioned companies. They own the data which powers the analytics. The layer above is the consumer or enterprise-facing platforms, which organise this data and present it in an appealing way for practical use. So that professional investors, advisors, and even retail investors can analyse markets, track portfolios, and so on.
The aforementioned companies also play in this space. Morningstar has Morningstar Direct, S&P has Capital IQ, Bloomberg has the Terminal, Factset has its version of the terminal, and LSEG has LSEG Workspace. This layer is also home to an abundance of other platforms that use the kingpin’s data. Examples include Quartr, Koyfin, TradingView, Ycharts, Fiscal AI, and many more. Some, like TIKR, are almost exclusively wrappers.
Others, such as Quartr, Koyfin, and Ycharts, have carved out niches in addition to serving a wider audience or have stitched together such a wide array of data from multiple vendors that they have less concentration risk. These companies offer tooling that does not exclusively resell vendor data at a lower price point. They provide value-added functionality such as portfolio analytics, integrations, reporting, and so on.
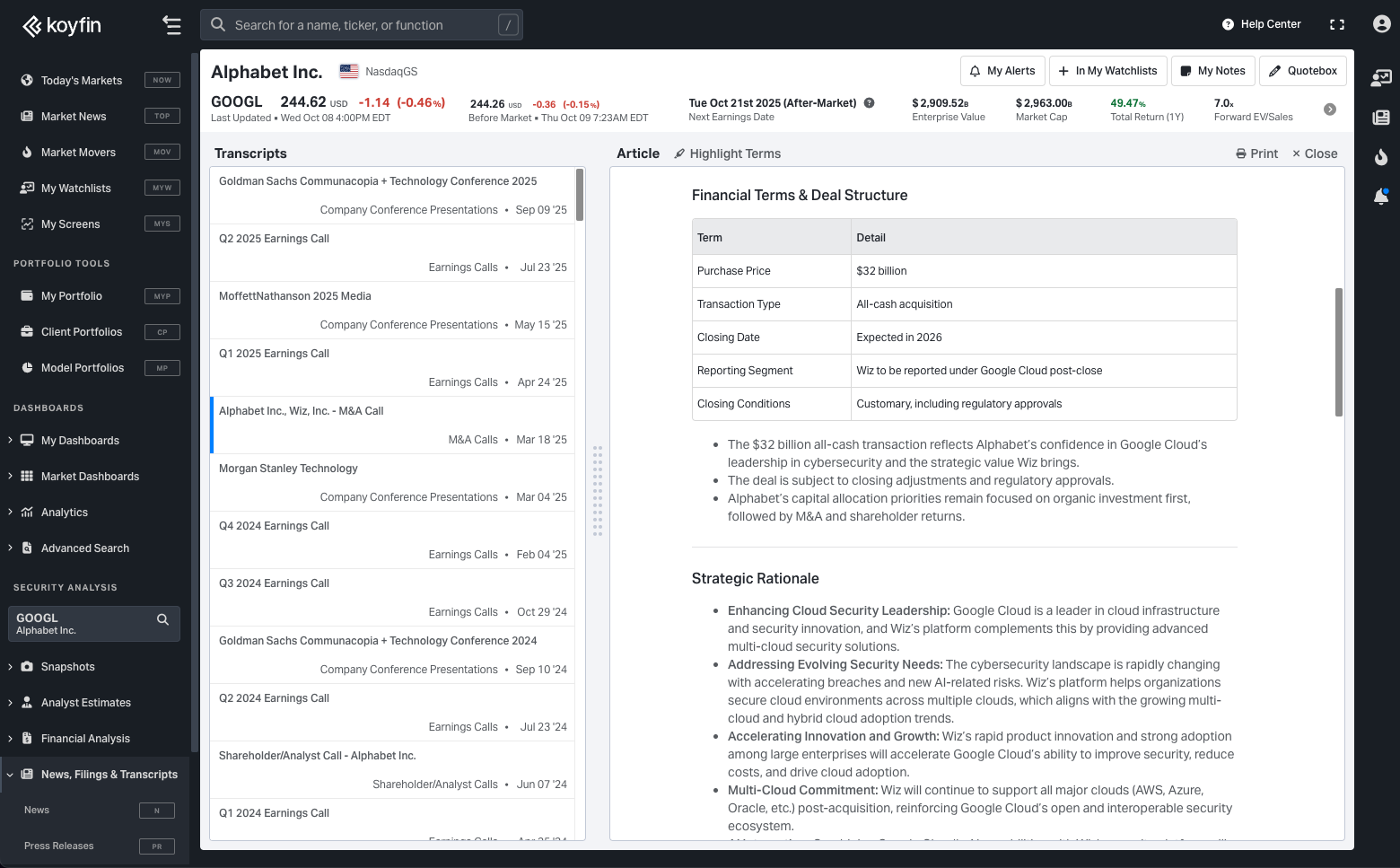
Fiscal AI is an interesting one because, on the face of it, they are a retail-focussed platform providing data on equities and funds, likely from ~3 big vendors. However, this particular company has taken steps to shed the handcuffs of the Big 5 and is now creating its own dataset. The first example is their innovative approach to Segment & KPI data. Instead of licensing, they collect it themselves. Which means they can now license it to others (Ycharts being one example, Perplexity being another).
More recently, they have made efforts to start collecting standard financial data from filings, displacing their need to license data from Capital IQ. A filing comes in, they scrape it using LLMs, they populate the data in their database, and this flows onto their platform. Fiscal AI is, in effect, an API business.
To simplify, think of it this way:
Morningstar is in the Vendor business: They collect, aggregate, and clean data, store it in databases, and license it to other businesses.
Koyfin is in the Value-Added Distributor business: They license data from several vendors and distinguish themselves by offering value-added services such as advanced visualisation, data transformation, analytics, and unique tooling.
TIKR is in the Reseller business: They license data from vendors without much added value and resell it.
The important distinction here is that distributors and resellers don’t own the data. The equally important caveat, however, is that the industry isn’t quite so simple. Morningstar, Capital IQ, LSEG, Bloomberg, and the other vendors are rarely ever pure vendors.
Capital IQ, for example, is a vertically integrated data provider. They own the underlying data and the software layer which commercialises it. On top of that, it also relies (albeit to a significantly lesser extent than non-vendors) on third-party vendors for some of the data it licenses and includes in its platform. The same is true for Morningstar and LSEG.
What is interesting about Fiscal AI is that they, more than anyone, pose a direct threat to the likes of Standard and Poor’s Capital IQ. Fiscal AI is attempting to compete at both layers of the market, as a vertically-integrated vendor.
Competitive Advantage Narrative
The rise of LLMs has people questioning if this competitive advantage will hold for the Big 5, given that it is now easier to extract this information independently, both for consumers and for enterprises. Thus, bypassing the expensive licensing costs. In practical terms, this suggests the barriers to entry have declined. Fiscal AI is evidence of that trend. Initially starting life as a reseller, the company has since become a vendor.
As a product manager who is often in contact with data vendors, I have noticed a spike in start-ups aspiring to replicate this model. Many of which are using LLMs to extract data from filings to create a database of global financial metrics, which they can either use to create their own platform or sell to other platforms.
This theme appears to be puncturing the Big 4’s returns (excluding Bloomberg, which is not publicly traded). Since 2024, the companies have declined between 28% (in LSEG’s case) and 42% for Factset.

I suspect this is a great thing for the consumer. As Peter Thiel once said9, “competition is for losers”. There are most certainly other factors at play here. You can paint any narrative about historical price action that fits. Whatever the case, I find the argument to be slightly flawed.
Take LSEG as an example. It’s an incumbent. One of the criticisms of products like LSEG Workspace (and other ‘terminals’) is that they are slow to innovate and have UI that looks like it was etched into stone during the 1990s. They are often built on older technical infrastructure, making evolution slower. Contrary to that argument, Workspace actually looks modern with a modular interface. The same can’t be said for all platforms.
Anyway, LSEG has been talking about AI workflows for years. In their H1 2025 earnings call, they highlighted several initiatives ranging from agentic analytics, co-pilots, natural language search and data prompts, and AI-generated news.
LSEG’s CEO, David Schwimmer, has been vocal about how important these advancements are and takes a view of welcoming the technology shift. In his view, AI enhances, not replaces— “the future is AI integrated into a desktop, not AI replacing a desktop”.
He is referring to the idea that because AI lowers the barriers, it means the competitive advantages of LSEG (and other vendors) are at risk. In reality, cheaper alternatives have been available for decades. Nothing personifies this better than the ‘Bloomberg Killer’ idea.
Now and then, a tweet will go viral that either;
A: Questions why Bloomberg hasn’t been replaced yet,
B: Suggests [product X] will replace Bloomberg
C: Claims it would be easy to build a Bloomberg killer
D: Some mixture of the above
It almost always captures a lot of attention. The author is almost always entirely ignorant. Here’s the reality of the situation:
People don’t understand why Bloomberg is an institution: Bloomberg is like the Swiss Army Knife of markets on viagra and steroids. It does everything. It has a professional network effect. It provides niche datasets that nobody else provides. It is, in effect, not replaceable by some users because it’s a mission-critical software. Commonly, people look at Bloomberg and then compare it to Yahoo Finance and say something naive like “Yahoo has live stock quotes for free”. They are not serious people.
What is not happening: Bloomberg is not in the business of competing with retail platforms for mass market adoption. The price point alone is the greatest signal of that. Most cited ‘Bloomberg Killers’ are retail platforms. It’s apples to oranges.
What is happening: There is genuine displacement occurring for investors who use Bloomberg, but only use a fraction of the more basic capabilities of the Terminal. To give just one example, Financial Advisors. They can live without Bloomberg and substitute their needs with platforms like Factset, Koyfin, and Morningstar. Another example is Investor Relations departments, which could replace a terminal with Quartr. However, this is not a new trend.
Back to LSEG for a moment. David Schwimmer’s confidence is warranted. There are undoubtedly going to be a lot of great innovations in the retail space. LSEG are selling to the same people that the rest of the Big 5 are. Those companies are all incorporating LLMs into their workflows. So while it feels like groundbreaking stuff is happening, I sense that it’s more ‘business as usual’ for the most part. At least in the medium term.
During the H1 call, they were also asked about this theme of new entrants, to which Schwimmer expressed an opinion I largely agree with. It’s less about having a cool UI; the advantage still lies in the quality of data.
LSEG are not selling to 20-somethings with a $25k portfolio. That’s not their market. Any professional or serious investor cares about data quality, and that is the Big 5’s manifesto. They own it, they have large quality assurance teams to maintain it, and they provide estimates and other proprietary data. The question from the call reads as follows:
“There’s been some worry in the market about that as a sort of disruption risks in workflow to the industry as a whole from sort of new fintech AI platform”.
Schwimmer’s response, which I will largely leave un-edited, reinforces the idea that professionals care most about data quality, availability and, importantly, auditability. These less price-sensitive customers want the best.
“You can have a really cool user interface, but the quality of the product depends on the quality of the data. And we have the broadest, the deepest, the highest quality data sets. The second point I would make is that users don’t want just a sophisticated -- I used this phrase before, sophisticated chatbot. They want that great AI functionality, and they want that AI functionality embedded in all of the other workflows. And that can be news curation, charting, order and execution management, analytics, risk systems. We provide all of that in our user interface, in Workspace. And we are building AI into all of that.
And so I think that’s a really important aspect of this in terms of -- again, you can have, as I said, sort of a cool user interface, but that on its own doesn’t get you there in terms of what our industry is looking for and what our industry expects. Our users also want that workflow and that AI capability to be interoperable with their enterprise workflow. And then the last point, I touched on this earlier, but the last point, I think you cannot emphasize enough is that users want data that they can trust and they can rely on. And so with respect to some of the new offerings that are out there, and we’ve seen and we’ve played with some of the flashy demos and other things. But in one of those in particular, that has gotten a lot of attention, if you go into their own press release, there’s -- that press release points to their -- there’s a link in that points to what they’re relying on and their accuracy in finance is at 51%. And their accuracy in market analysis, they don’t define what market analysis is, but I think we do a lot of market analysis. Their accuracy and market analysis is 14%.
So I think coming back to your question in terms of some of the fintech offerings, they may be cool and they may be fun to try out, but they cannot meet the demands of this sector, the demands of our customers today. And I think that’s really important to keep in mind.
We are embedding AI functionality in our offerings, and we’re certainly not sitting still. So I think -- and there’s more to come. So as I said before, I like our positioning. We welcome the tech innovation. We welcome the tech change.
Two of the biggest takeaways after reading this for me were the comment on the sophisticated chatbot and the importance of audibility, which is essentially the element of trust in the output.
When he said “users don’t want just a sophisticated chatbot”, this resonated with me. At Koyfin, we’ve been patient with how we incorporate LLMs into our platform, and only now do we have an exciting roadmap of features. I am grateful we were patient because we’ve had the advantage of learning from the mistakes of peers.
I will preface this next part with some admiration first.
Fiscal AI’s Evolution
I have enjoyed watching the trajectory of Fiscal AI (formerly Finchat, formerly Stratosphere). I have huge respect for Braden (Co-founder) and their team. They do a lot of things right, and it’s refreshing to see a business that ships fast, ships hard, and spends time on features they know users will love. While there is some intersection between users (i.e some users will directly compare Koyfin and Fiscal AI in a purchasing decision), I believe the goals of each company are quite removed. I won’t comment too much on that, but the intersection exists at the retail investor level. Where it differs is that Fiscal AI are an API business, and Koyfin have a growing market share in serving Advisors (an area Fiscal AI is not currently in).
To put it another way, the two companies are as likely to be competitors as they are partners10. Koyfin licenses high-quality data. Fiscal AI sell high-quality data to enterprises.
Admiration segment complete, one learning I have passively absorbed from Fiscal AI is that they learned that users don’t want a “sophisticated chatbot” the hard way.
Several years ago, Fiscal AI was called Stratosphere. Stratosphere was a reseller platform. Then one day, the same minds that built the Stratosphere created a beta application called Finchat.io, which was essentially an LLM wrapper come chatbot which plugged into Stratosphere’s data. This was incredibly novel at the time, I must say. While the two products were connected on the backend, they were two separate offerings. One day, around 2023, the team decided to merge the two and create Finchat.
Finchat would essentially rebrand the Stratosphere platform, make it look a lot cleaner and more terminal-like. Only now, the Co-Pilot (a rebranded version of Finchat.io) was the central feature on the platform. The co-pilot was a ‘do everything’ chat interface powered by LLMs and Fiscal AI’s data. It was an impressive feature, but I got the sense it was a jack of all trades, master of none. You could try to run a screener, generate a report, ask it questions about filings, and tell it to build tables. Yet, it was never clear what its superpower was.
Around a year later, the co-pilot, which was once the primary driver of the platform, was relegated to a left-hand-side navigation element. It became more of a ‘feature’ than a flagship staple of the platform. Then, in 2025, another rebrand came along. Finchat became Fiscal AI. In a press release statement, the company claimed:
“As we’ve grown, so have our ambitions — beyond the Chat interface. Fiscal.ai represents a bold new vision: to power modern financial data infrastructure through our Terminal and APIs, transforming how the world accesses and uses information in capital markets”.
Behind the scenes, the company was quietly planning to shelve the co-pilot. On August 19th, 2025, Braden would reply to a user on Twitter that “copilot is being retired soon”. As of today, the co-pilot no longer exists on the platform.
Braden shared the story on a podcast I listened to a few months back. There, he explained that they started to license the API for this co-pilot, it grew traction, and then stuttered as the churn rates were high. To their credit, they bit the bullet and moved forward quickly. I think this was a smart move on their part.
Where Fiscal’s co-pilot failed, I believe, is due to generalisation. It lacked a workflow-specific focus and was never quite good enough at any particular flow to warrant that desired stickiness. It was arguably better than ChatGPT at some flows, but not by a significant enough margin.
There needs to be some kind of super-intuitive and workflow-driven element to an LLM feature; otherwise, it just becomes a feature that tries to do too much at once. A sophisticated chatbot, as Schwimmer puts it.
Workflow Enhancement
Let’s use Quartr as an example, another player in this space I have a lot of admiration for. They introduced a chat interface feature (I know I just poo-poo’d this, but hear me out). The important difference, however, is how this product is marketed. From the get-go, it’s incredibly clear what this feature is for. It queries information from documents (filings, transcripts, press releases).
You ask questions, it searches the database and spits out a response. In the mind of the user, you have the expectation that it does this workflow well. Unlike Fiscal’s co-pilot, which had less of a defined use case, users won’t feel slighted by the fact that it doesn’t function as a charting tool or a screener, because it was never marketed as such. I have used Quartr’s document query engine, and it was a remarkably better experience.
These days, many investors are downloading transcripts and filings and dropping them into generic LLMs like ChatGPT or Notebook LLM. The obvious problem here is that (a) these LLMs are not tailored to this workflow and (b) they don’t sit on top of a structured database of the required data. In other words, you need to give them the data, then they analyse it. Quartr’s product is built on top of the data, meaning you don’t need to carry your digital briefcase of filings around with you. The irony here is that Fiscal’s co-pilot could perform the same kind of use case, and it was launched almost 2 years prior. I have no idea about the commercial success of Quartr’s product, but it felt like a solid feature when I used it. There was more of an intuitive moment of “oh, this is what this thing does”.
Takeaway
Over time, I am gravitating to the idea that LLM-enabled tools need to be built to enhance a workflow. Not starting from the LLM and saying, “How many different things can we make this do at once?”. Alternatively, they should create brand new workflows that were previously not possible. Genuine novelty, unlocking new patterns while avoiding the trap of confusing novelty for utility.
I am incorporating this belief as we work on the exciting roadmap we have at Koyfin. I’m dying to share what we are working on, but given that some are truly unique in nature, I will be keeping the wraps on it for now. But what I will say is that it plays into this idea that you should start with the workflow first, and imagine how LLMs enhance that… with a little extra.
Like any good product/feature, it should be intuitive and obvious what it does, and not require a ton of instructions and articles.
Thanks for reading,
Conor
A feature which is referred to as table stakes implies it’s a basic, must-have feature and something expected in your product category. Interestingly, if we had released this feature 3 years ago, it would have been fairly novel. Such is the rate of progress of AI.
For context, I do think there is a use case for these hyper-short summaries, but our approach is targeted to the fundamental investor, who cares about more than the headline figures.
Spoiler, they are not.
Intuit Analyst Day, September 18th, 2025.
LSEG H1 2025 Results Call, July 31st, 2025.
Working with AI: Measuring the Applicability of Generative AI to Occupations (2025). Kiran Tomlinson, Sonia Jaffe, Will Wang, Scott Counts, and Siddharth Suri, Microsoft Research (here).
There are several other companies (e.g Moody’s) I decided not to include here, for simplicity’s sake.
At this time, Koyfin does not have any existing partnership with Fiscal AI.
Was this written by AI or do you really believe SMCI is a valid peer 😆?
Can LLM read between the lines on conference calls to understand why the most important sell side analyst questions are often disguised so that other analysts on the call won't be able to gather the insights sought from the answer. If you're just listening to the management, you'd be better off not listening. Similarly, if you're listening to the softball pitcher analysts who are just teeing up the ball. I doubt LLM will add buyside value to be honest. They may be better at providing support for investment decisions that don't add value.